
Ikegami TECH
2024.12.11
Ikegami TECH vol.38 画像圧縮Part2 ~動画を圧縮する技術~

画像圧縮Part2 ~動画を圧縮する技術~
前回の静止画の画像圧縮技術に引き続き、今回は動画の画像圧縮技術について解説します。
前回示したように、FHDの1秒間のデータは約187MByteと静止画像と比較して情報量(データ量)はとても多くなります。例えば10分の動画を記録する場合、単純に計算してデータ量は約113GByteに達します。つまり、動画を簡便に記録、伝送するためには静止画よりも更に圧縮(情報量を削減)する必要があります。
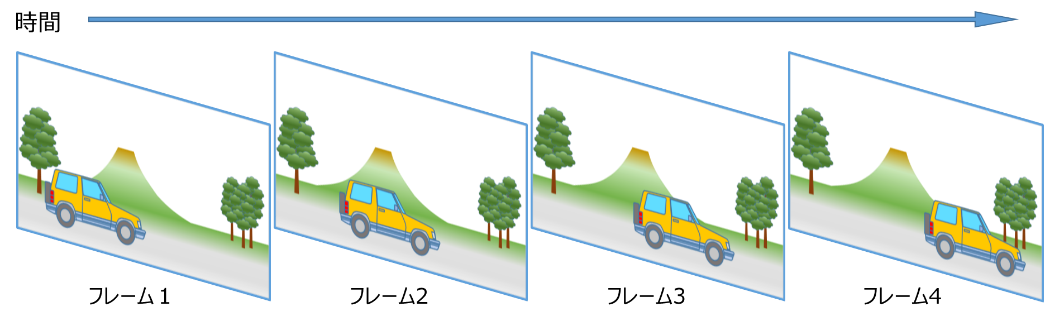
ここで、左から右に動いている車を撮影した動画を思い浮かべて下さい。動画は図1に示すように車が少しずつ移動した静止画(フレーム)が連続している構造となります。各静止画(フレーム)は少しづつ変化していますが、背景や移動している車など多くの共通した画像を含んでいます。動画像の圧縮は、このフレーム間で共通する画像情報(時間的冗長性)を削減することで大幅な圧縮を実現しています。
動画圧縮の流れ
動画圧縮も静止画のときと同様、次の3つのステップで行われます。
① 冗長度抑制(フレーム間予測、動き補償、直交変換(DCT))
② 量子化
③ エントロピー符号化
フレーム間で共通する画像情報(時間的冗長性)の削減処理は①の「フレーム間予測」、「動き補償」の2つの技術で行われます。ここでは、動画圧縮に特化した、これらの技術について概要を解説します。
フレーム間予測
フレーム間予測とは、動画は時間的に近接しているフレーム間では共通する画像情報を多く含むことを前提に、その共通する画像情報の冗長性(時間的冗長性)を削除することで動画圧縮を向上させる技術の総称になります。ここでは次の3つのフレーム間予測について解説します。
①単純なフレーム間予測
②前方向動き補償フレーム間予測
③双方向フレーム間予測
①単純なフレーム間予測
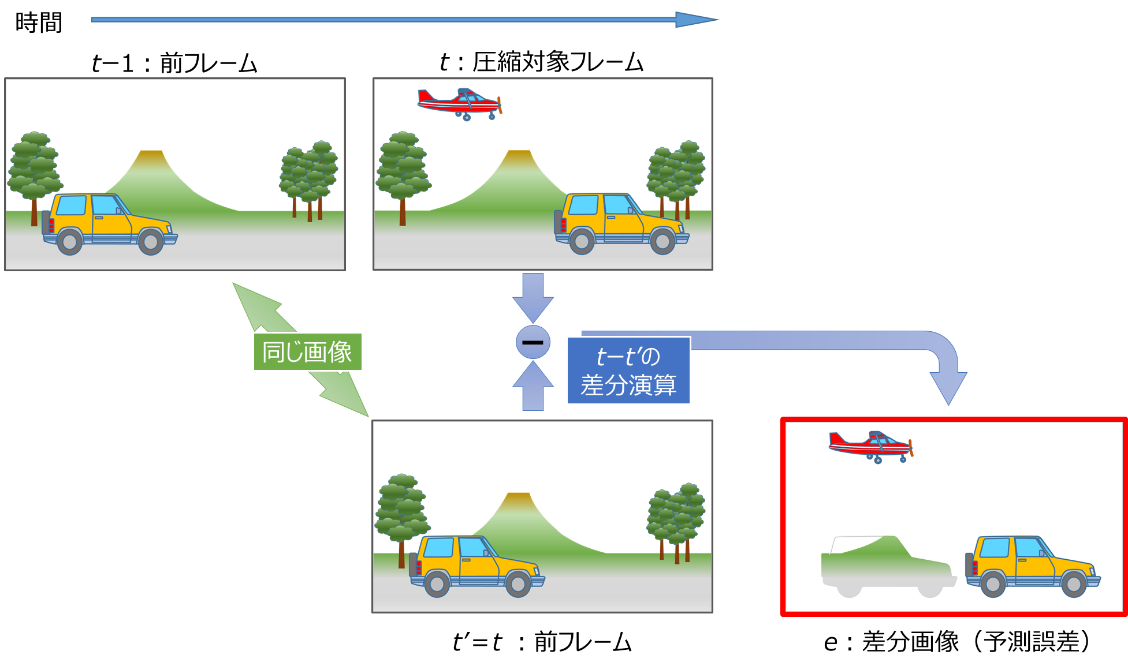
図2に圧縮対象のフレーム(t)と時間的に前のフレーム(t-1)との差分による、単純なフレーム間予測の例を示します。ここではわかりやすいように、便宜上、差分画像を上書画像として表現しています。
図2のフレーム間の差分で得られる差分画像(e)は、動きのある車と飛行機のみが現れ、両フレーム共通の背景は消えて情報量が削減されていることがわかります。つまり、この差分画像(e)の情報のみから、対象フレーム(t)は前フレーム(t-1)に加算することで復元できますので、大幅な圧縮を実現できます。
ただし、この単純なフレーム間予測ではカメラワークによる背景の動きや、動きの早い物体が多く撮影されている動画では、差分画像の情報量が多くなり時間的冗長性の削減効果が低くなります。そこで、一般的には次の動き補償を伴ったフレーム間予測が利用されています。
②前方向動き補償フレーム間予測
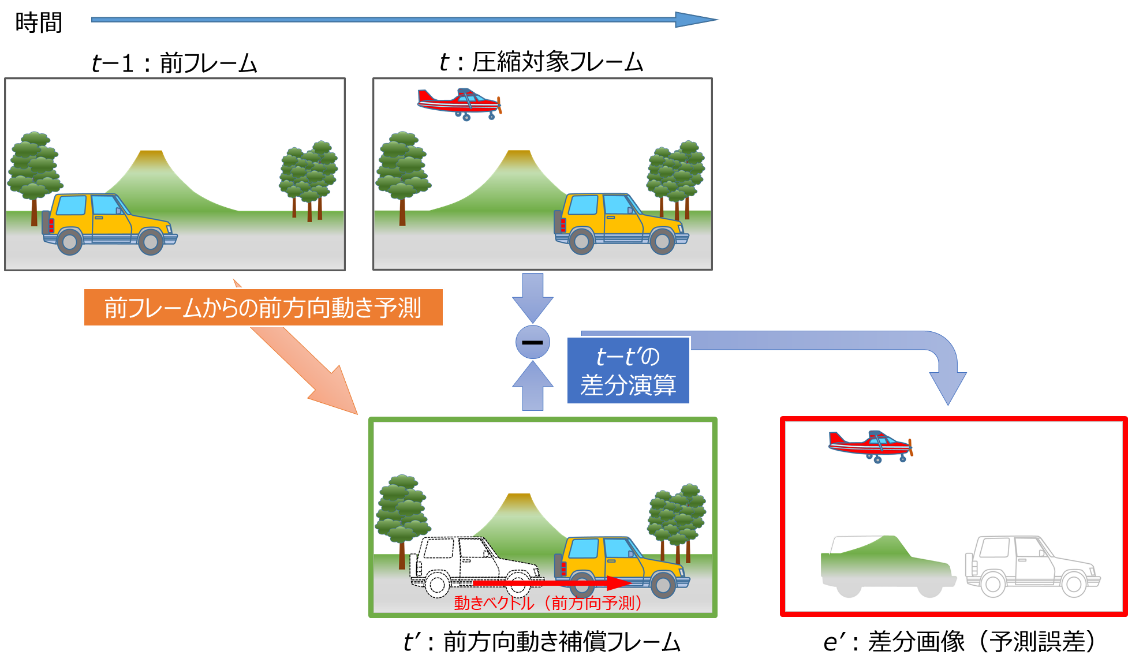
図3に前フレームからの動き補償フレーム間予測の例を示します。
前フレーム(t-1)と圧縮対象フレーム(t)で左から右に移動して写っている車に注目します。車は両フレームで形状が同じ共通の画像情報ですから、次の手順で移動後の車を削除した差分画像により更に圧縮の向上が図れます。
- 前フレーム(t-1)の車が圧縮対象フレーム(t)でどこに移動したかの「動きベクトル」(動いた方向と量)を求める。
- 動きベクトルをもとに前フレーム(t-1)で車を移動させた予測画像(t':前方向動き補償フレーム)を作成する。
- 圧縮対象フレーム(t)と前方向動き補償フレーム(t')との差分をとり差分画像(e')を求める。
図2と図3の差分画像を比較すると、図3では移動先の車の情報が削減され圧縮の向上が図れることがわかります。
③双方向動き補償フレーム間予測
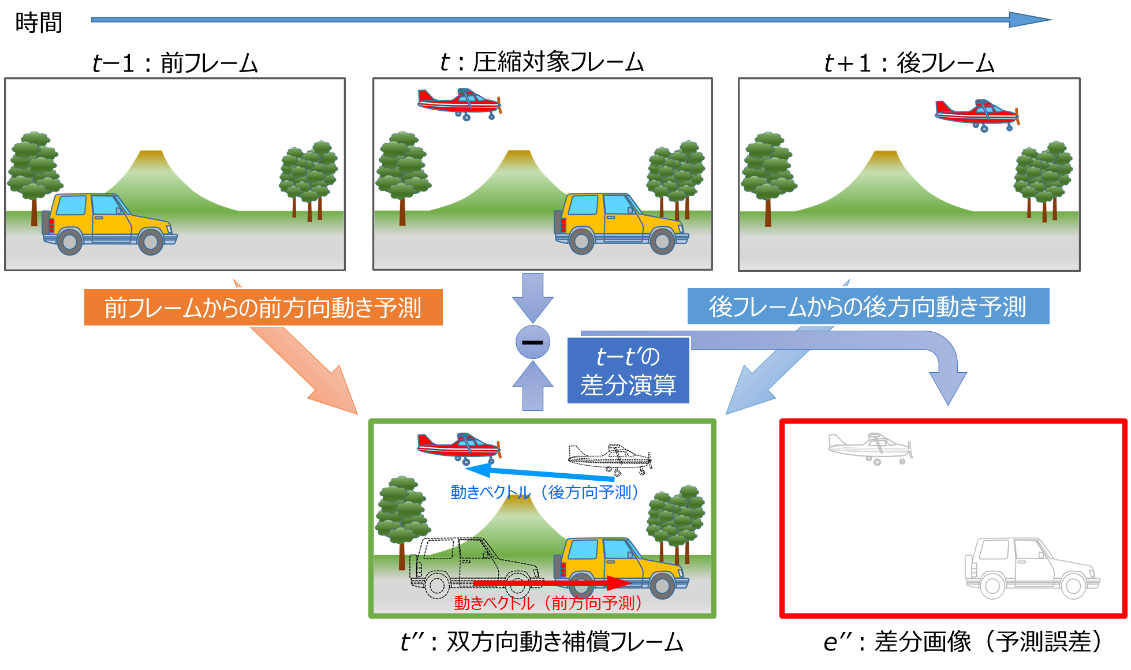
図4に双方向動き補償フレーム間予測の例を示します。これは、前述の動き補償フレーム間予測を拡張し、時間的に進んだ後のフレームも参照して動き補償を行う技術です。
図4の例で作成されている双方向動き補償フレーム(t'')では、図3の前方向動き補償フレーム(t')に、圧縮対象フレーム(t)と後フレーム(t+1)から共通の画像情報の飛行機の時間的に逆の動きベクトルを求めて作成した予測画像を加えています。さらに、前フレーム(t-1)の車で隠されていた背景も予測画像として加えられます。これにより、圧縮対象フレーム(t)と双方向動き補償フレーム(t'')との差分画像(e'')は、ほとんどの情報が削減され、効果的な圧縮を実現できることがわかります。
以上から動画を最も圧縮する理想的な構造として、最初に基準となる画像(フレーム)があり、その後に続くすべてのフレームを差分画像で構成することが考えられます。しかし、この構造では常に再生は最初から行わなくてはならず、任意フレームからの再生はできません。また、フレーム(差分画像)の一部データが失われた場合、失われたフレームが正しく復元できないばかりか、画像再生が終了するまで影響が続いてしまします。そこで、一般的には次に示すようなフレーム構造が取られています。
動画圧縮のフレーム構成
動画圧縮のフレーム構成の一例を図5に示します。各フレームは次の3種類から構成されています。
- I(Intra Coded Picture)
フレーム間予測を行わず、静止画圧縮のようにフレーム内の情報のみで圧縮されているフレーム。ランダム再生の開始点や編集点として利用。さらに、動画復元時にデータ・エラーや欠損の影響を伝搬させない働きもある。 - P(Predictive Coded Picture)
時間的に以前のIフレームまたはPフレームを参照して前方向動き補償フレーム間予測により圧縮されるフレーム。 - B(Bidirectionally Predictive Coded Picture)
時間的に以前、以後の両者のIフレームまたはPフレームを参照して双方向動き補償フレーム間予測により圧縮されるフレーム。
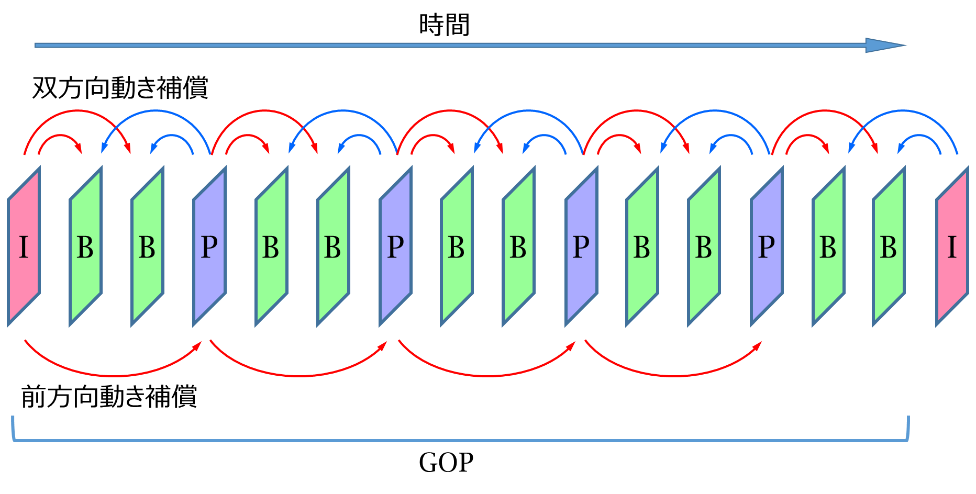
また、一つのIフレームと複数のPおよびBフレームをまとめたものをGOP(Group of Picture)と呼び、ランダム再生やトリックモード再生(高速再生、逆再生など)時に、このGOP単位にアクセスを行い処理することで可能にしています。
このように、動画圧縮技術はフレーム間で共通する画像情報(時間的冗長性)を巧みに削減し、フレーム構成の工夫で大幅な圧縮と再生時の利便性の両立を実現しています。
関連記事を読む
-
Ikegami TECH

Ikegami TECH Vol.57 FPUの小型軽量化技術 ~機動性と信頼性の実現のために~ Part.2
-
Ikegami TECH
Ikegami TECH Vol.56 FPUの小型軽量化技術 ~機動性と信頼性の実現のために~ Part.1
-
Ikegami TECH
Ikegami TECH vol.55 ヘリ空撮映像からの位置特定 ~高精度な撮影位置の測定と地図連動技術による災害対応への貢献~ Part.2
-
Ikegami TECH
Ikegami TECH vol.54 ヘリ空撮映像からの位置特定 ~高精度な撮影位置の測定と地図連動技術による災害対応への貢献~ Part.1
-
Ikegami TECH
Ikegami TECH vol.53 耐放射線性カメラの特性 ~映像技術で過酷な環境下の作業を支えるために~ Part.2
-
Ikegami TECH
Ikegami TECH vol.52 耐放射線性カメラの特性 ~映像技術で過酷な環境下の作業を支えるために~ Part.1
-
Ikegami TECH
Ikegami TECH vol.51 電波は限られた資源 ~周波数特性と最適なシステム構成~
-
Ikegami TECH
Ikegami TECH vol.50 リターンとタリー ~システムカメラならではの機能~
-
Ikegami TECH
Ikegami TECH vol.49 無線伝送とOFDM ~効率よく安定して伝える技術~ Part3
-
Ikegami TECH
Ikegami TECH vol.48 無線伝送とOFDM ~効率よく安定して伝える技術~ Part2
-
Ikegami TECH
Ikegami TECH vol.47 無線伝送とOFDM ~効率よく安定して伝える技術~ Part1
-
Ikegami TECH
Ikegami TECH vol.46 複数のHD映像を簡単に長距離伝送したい ~HD多重伝送におけるクロック再生技術~
-
Ikegami TECH
Ikegami TECH vol.45 光の三原色ですべての光の色を表現できる?
-
Ikegami TECH
Ikegami TECH vol.44 デジタルシステムへの「段階的」な移行 ~既設機器を活かした効果的な更新計画~
-
Ikegami TECH
Ikegami TECH vol.43 技術の進歩がもたらした"便利"と"ジレンマ" ~デジタルによりシンプルになった技術とアナログの方がシンプルだった技術~
-
Ikegami TECH
Ikegami TECH vol.42 プロダクトデザイン ~モノづくりメーカーが創る価値あるデザイン~
-
Ikegami TECH
Ikegami TECH vol.41 テレビのアスペクト比の変遷 ~4:3から16:9へ、その次は?~
-
Ikegami TECH
Ikegami TECH vol.40 途絶えない通信を目指して ~光通信×無線のハイブリッド戦略~
-
Ikegami TECH
Ikegami TECH vol.39 放送用カメラの望遠 ~遠くのものを一瞬にして拡大する技術~
-
Ikegami TECH
Ikegami TECH vol.37 画像圧縮Part1 ~静止画を圧縮する技術~
-
Ikegami TECH
Ikegami TECH vol.36 デジタルデバイス技術発展の歴史 ~Ikegamiカメラの技術で振り返る~
-
Ikegami TECH
Ikegami TECH vol.35 もう一つの検査 表面検査技術について ~微小な欠陥を見抜く技術~
-
Ikegami TECH
Ikegami TECH vol.34 映像伝送における光ファイバー技術の活用 ~高い耐環境性で早く遠くへ届ける技術~
-
Ikegami TECH
Ikegami TECH vol.33 SNMPプロトコルによる一元管理と効率的な運用 ~生放送を前提とした放送システムでの活用~
-
Ikegami TECH
Ikegami TECH vol.32 画像の鮮明化 番外編 ~Retinex理論による画像鮮明化~
-
Ikegami TECH
Ikegami TECH vol.31 画像の鮮明化 ~見えにくいものを見やすくする技術~ Part2
-
Ikegami TECH
Ikegami TECH vol.30 画像の鮮明化 ~見えにくいものを見やすくする技術~ Part1
-
Ikegami TECH
Ikegami TECH vol.29 防振カメラのしくみ ~上空からヘリ映像やマラソン中継でもブレない映像を~
-
Ikegami TECH
Ikegami TECH vol.28 放送用カメラの機能をひも解く ~アナログ技術からの継承~
-
Ikegami TECH
Ikegami TECH vol.27 裸眼3Dディスプレイ ~人の眼の不思議!進化する立体技術~
-
Ikegami TECH
Ikegami TECH vol.26 オフラインでも正確な時刻同期 ~時刻合わせは宇宙から~
-
Ikegami TECH
Ikegami TECH vol.25 放送用カメラの機能をひも解く ~現場発想で新たな機能に~
-
Ikegami TECH
Ikegami TECH vol.24 光の線で3次元形状計測 ~小さなキズも見逃さない技術~
-
Ikegami TECH
Ikegami TECH vol.23 テクノロジーを結集させる技術力で変わるワークフロー
-
Ikegami TECH
Ikegami TECH vol.22 無駄なトラフィックを削減 ~データが欲しいのは誰なのか?~
-
Ikegami TECH
Ikegami TECH vol.21 暗闇だけでない、見えないものを見られる技術! ~赤外線カメラについて~
-
Ikegami TECH
Ikegami TECH vol.20 もうひとつの本線映像~ビューファインダー技術について~
-
Ikegami TECH
Ikegami TECH vol.19 感度と解像度の両立~メディカルカメラの画素ずらし技術~
-
Ikegami TECH
Ikegami TECH vol.18 暗闇から研ぎ澄ました光の中へ~高感度カメラについて~
-
Ikegami TECH
Ikegami TECH vol.17 映像同期はなぜ必要なのか?
-
Ikegami TECH
Ikegami TECH vol.16 温故知新 ~放送設備のIP化を考える~(2)
-
Ikegami TECH
Ikegami TECH Vol.15 温故知新 ~放送設備のIP化を考える~(1)
-
Ikegami TECH
Ikegami TECH Vol.14 モニターの“表示デバイス”種類やその特長は?(2)
-
Ikegami TECH
Ikegami TECH Vol.13 モニターの“表示デバイス”種類やその特長は?(1)
-
Ikegami TECH
Ikegami TECH Vol.12 算数でひも解くデジタル映像処理(2)
-
Ikegami TECH
Ikegami TECH Vol.11 算数でひも解くデジタル映像処理(1)
-
Ikegami TECH
Ikegami TECH Vol.10 医療を支える映像技術
-
Ikegami TECH
Ikegami TECH Vol.9 走っている車のタイヤが止まって見える!
-
Ikegami TECH
Ikegami TECH Vol.8 没入感だけではない? 8K技術が支える新たな体験
-
Ikegami TECH
Ikegami TECH Vol.7 音声技術を追いかける映像技術
-
Ikegami TECH
Ikegami TECH Vol.6 「百聞は一見に如かず」を検証してみよう!
-
Ikegami TECH
Ikegami TECH Vol.5 究極のデジタルはアナログか?
-
Ikegami TECH
Ikegami TECH Vol.4 量か質か?
-
Ikegami TECH
Ikegami TECH Vol.3 被写界深度と奥行き
-
Ikegami TECH
Ikegami TECH Vol.2 夕焼けはなぜ赤い
-
Ikegami TECH
Ikegami TECH Vol.1 色温度と心理